General Flow
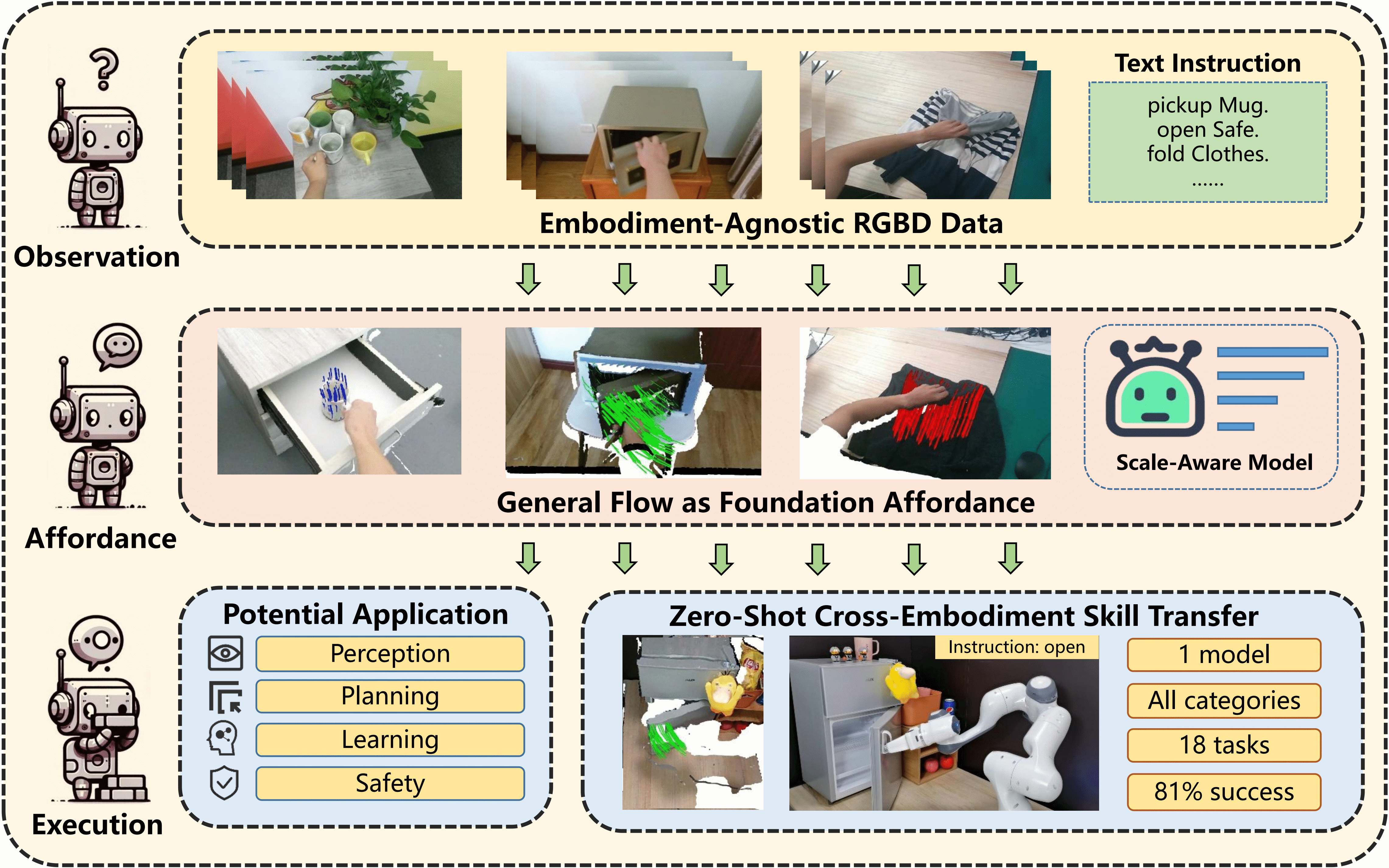
We propose General Flow as a Foundation Affordance. Its properties and applications are analyzed to reveal its great power. We design a scale-aware algorithm for general flow prediction and achieve stable zero-shot cross-embodiment skill transfer in the real world. These findings highlight the transformative potential of general flow in spearheading scalable general robot learning.
Zero-Shot Real World Execution
For all 18 tasks, we provide 4 human videos example and 3 demos of robot trials. We keep gripper position, grasp manner, initial state, scene setting and policy behaviour as diverse as possible. Please check out our paper for detailed method and deployment setting.
Video Demo for
with "
" action.
Video Examples from Human Datasets
Real World Trial-1
Real World Trial-2
Real World Trial-3
Zero-Shot General Flow Prediction
We provide visualiaztion for general flow prediction during zero-shot execution. 25 trajectories are selected for clearity. General Flow prediction is robustness to embodiment-transfer and segmentation error to some extend.
Visualization for
with "
" action.
_scene.png)
Scene Reference
_robot.png)
General Flow Prediction
More Visualization from Human Videos
We provide more visualiaztion of prediction on human videos. 25 or 50 trajectories are selected for clearity.
select
of visualization.

Emergent Properties of General Flow
When trained on the general flow prediction task at scale, our model acquires multiple emergent properties that are unfeasible in a small-scale imitation learning setting.
- Semantic Richness & Controllability [(a)(b)]: The semantics of the flow can be easily altered by switching language instructions, showcasing the model's flexibility.
- Robustness to Label Noise [(c)(d)]: Despite severe noise in labels, such as significant deviation in 'open Safe' or almost static labels in 'pickup Toy Car', our model consistently predicts the correct trend. In the figure, red indicates the label and green represents the prediction.
- Spatial Commonsense Acquisition [(e)(f)]: For instance, in task 'putdown Mug', the model adjusts its prediction scale to accurately reflect the spatial relationships of objects, ensuring both ends are on the table and adapting to longer distances with a larger scale.
- Semantic Richness & Controllability [(a)(b)]: The semantics of the flow can be easily altered by switching language instructions, showcasing the model's flexibility.
- Robustness to Label Noise [(c)(d)]: Despite severe noise in labels, such as significant deviation in 'open Safe' or almost static labels in 'pickup Toy Car', our model consistently predicts the correct trend. In the figure, red indicates the label and green represents the prediction.
- Spatial Commonsense Acquisition [(e)(f)]: For instance, in task 'putdown Mug', the model adjusts its prediction scale to accurately reflect the spatial relationships of objects, ensuring both ends are on the table and adapting to longer distances with a larger scale.

Failure Case
Trajectory Deviate
Gripper Drop
Robot Stuck
Please check out our paper for more details. Have fun :)
BibTeX
If you find this repository useful, please kindly acknowledge our work :@article{yuan2024general,
title={General Flow as Foundation Affordance for Scalable Robot Learning},
author={Yuan, Chengbo and Wen, Chuan and Zhang, Tong and Gao, Yang},
journal={arXiv preprint arXiv:2401.11439},
year={2024}
}